线程池
线程池的意义:频繁的创建和销毁线程,性能开销比较大。线程池创建一些线程,执行完任务后不立即销毁,可以等待去执行下一个任务
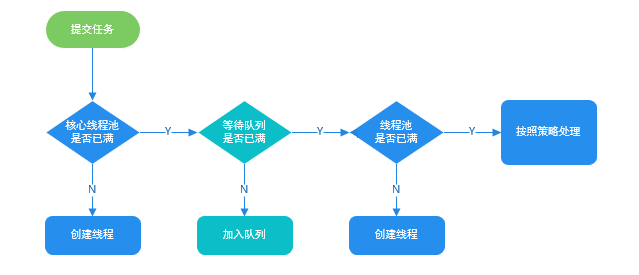
线程池相关参数:
|
|
线程池支持5种,Executors静态方法创建:
- FixedThreadPool:固定数量的线程,其他线程放入无界等待队列
- CachedThreadPool:线程数量不固定,无论多少任务都会不停的创建线程。线程空闲一定时间,释放线程
- SingleThread:线程池里只有一个线程,其他线程放入无界等待队列
- ScheduledThread:提交的线程,会在等待的时间过后才会去执行
- WorkStealingPool:底层使用forkjoin来执行
- newVirtualThreadPerTaskExecutor:jdk21新增,底层使用虚拟线程。不推荐使用,因为虚拟线程比较轻量不推荐池化。仅适用于项目虚拟线程改造,将原来线程池做简单替换。代码改动较少
|
|
工作队列
存放任务的工作队列有6种主要的实现,分别是 ArrayBlockingQueue、LinkedBlockingQueue、LinkedBlockingDeque、PriorityBlockingQueue、DelayQueue、SynchronousQueue。它们的区别如下:
- ArrayBlockingQueue:一个由数组结构组成的有界阻塞队列(数组结构可配合指针实现一个环形队列)。
- LinkedBlockingQueue:一个由链表结构组成的有界阻塞队列,在未指明容量时,容量默认为 Integer.MAX_VALUE。
- LinkedBlockingDeque:使用双向队列实现的双端阻塞队列,双端意味着可以像普通队列一样 FIFO(先进先出),可以以像栈一样 FILO(先进后出)
- PriorityBlockingQueue:一个支持优先级排序的无界阻塞队列,对元素没有要求,可以实现 Comparable 接口也可以提供 Comparator 来对队列中的元素进行比较,跟时间没有任何关系,仅仅是按照优先级取任务。
- DelayQueue:同 PriorityBlockingQueue,也是二叉堆实现的优先级阻塞队列。要求元素都实现 Delayed 接口,通过执行时延从队列中提取任务,时间没到任务取不出来。
- SynchronousQueue:一个不存储元素的阻塞队列,消费者线程调用 take() 方法的时候就会发生阻塞,直到有一个生产者线程生产了一个元素,消费者线程就可以拿到这个元素并返回;生产者线程调用put()方法的时候就会发生阻塞,直到有一个消费者线程消费了一个元素,生产者才会返回。
拒绝策略
内置的有4种拒绝策略
- AbortPolicy(默认):丢弃任务并抛出 RejectedExecutionException 异常。
- CallerRunsPolicy:由调用线程处理该任务。(例如io操作,线程消费速度没有NIO快,可能导致阻塞队列一直增加,此时可以使用这个模式)。
- DiscardPolicy:丢弃任务,但是不抛出异常。(可以配合这种模式进行自定义的处理方式)。
- DiscardOldestPolicy:丢弃队列最早的未处理任务,然后重新尝试执行任务。
当然也可以根据需求自定义拒绝策略,实现RejectedExecutionHandler接口即可
如何关闭线程池
shutdown:阻止新的任务提交,将线程池的状态改为shutdown,当再提交任务时,如果状态不为running,则执行拒绝策略。对于已提交的任务不会产生任何影响,如果还有任务未执行,线程将继续把任务执行完
shutdownNow:会关闭正在执行任务的线程,任务可能并没有执行完毕,关闭线程不需要等待
线程池核心线程数经验配置
CPU密集型任务:尽量压榨CPU,参考值设置为CPU的个数+1。
IO密集型任务:参考值可以设置为CPU的个数 ✖️ 2。
虚拟线程(jdk21新增):对于IO密集型任务,也可以改为使用虚拟线程。但需要代码中不使用synchronized关键字
线程池的好处
- 线程重用:线程的创建和销毁开销是巨大的,而通过线程池的重用大大减少了这些不必要的开销,当然既然少了这么多开销,其线程执行速度也是突飞猛进的提升。
- 控制线程池的并发数:线程不是并发的越多,性能越高,反而在线程并发太多时,线程的切换会消耗系统大量的资源,可以通过设置线程池最大并发线程数目,维持系统高性能。
- 线程池可以对线程进行管理:虽然线程提供了线程组操控线程,但是线程池拥有更多管理线程的API。
- 可以储存需要执行的任务:当任务提交过多时,可以将任务储存起来,等待线程处理。